
In our previous article on Generative Engine Optimization (GEO), we discussed the importance of Schema.org metadata as one of the key factors for improving your visibility in AI-generated responses. Today, we delve deeper into this topic to concretely explain what Schema.org is, how it works, and why it's particularly relevant for artists and cultural organizations.
Metadata: What Exactly Is It?
Before specifically talking about Schema.org, let's clarify some concepts, starting with metadata.
Metadata is simply data that describes other data.
Think of a book: the content of the book represents the main data, while the title, author, publication date, genre, and ISBN are metadata - they are not part of the story told, but they describe and contextualize the book.
On the web, metadata plays a crucial role in providing information about your pages and their content:
- They help search engines understand what your site is about,
- They enable better sharing on social networks,
- They facilitate the organization and retrieval of information.
Traditional Metatags vs. Schema.org
There are different types of metadata on the web, the most common being:
1. Traditional HTML Metatags
These simple tags are found in the header of your web pages and are not visible to ordinary visitors - they only appear in the page's source code:

These traditional metatags play an important role in the basic SEO of your site: the "description" tag often appears in search results under the title of your page, while other metatags help search engines understand the overall content of your site. For more information on the importance of these tags, check our article SEO Explained for Artists: How to Be Seen on the Web
Despite their usefulness, these metatags are limited: they provide a general description of the page but do not allow for the precise distinction of different information elements (who is the artist? what is the location? what is the date?).
2. Social Media Metatags
Formats such as Open Graph (for Facebook) or Twitter Cards allow for better display when sharing on social networks:

These tags are more advanced but remain limited to specific use cases.
3. Schema.org Structured Data
This is the most advanced and complete approach, which we will explore in detail in this article. Unlike simple metatags, Schema.org allows you to organize your information in a structured way and create explicit relationships between different elements.
What is Schema.org, in Simple Terms?
Imagine a modern library equipped with a computerized search tool. For this tool to operate effectively, each document must first be meticulously cataloged: is it a novel or a documentary? What is its main subject? Is it a book, a magazine, or another type of document? What audience is it intended for?
Without this meticulous cataloging work, the search tool would be practically useless – you'd be forced to browse the shelves randomly to find what you're looking for.
Schema.org plays exactly this role of cataloging system for the web. It allows you to classify and label your site's content precisely, creating a "catalog" that search engines can easily consult and understand.
Concretely, Schema.org:
- Provides a standardized vocabulary of tags and categories,
- Allows you to classify your content according to specific criteria (event, person, place, etc.),
- Establishes relationships between different elements (who participates in what, where does a particular event take place, etc.),
- Creates a common language that all major search engines understand.
Without Schema.org, search engines must "guess" what your site contains – a bit like looking for a book in a library without a classification system.
Who Defines This Vocabulary?
Schema.org is not an isolated project. It is a collaborative initiative founded in 2011 by the biggest search engines: Google, Microsoft (Bing), Yahoo, and Yandex. This collaboration ensures that the vocabulary is universally recognized and regularly updated to meet the evolving needs of the web.
The Schema.org vocabulary is maintained by an open community of experts and contributors. It constantly evolves to cover new domains and uses while remaining stable in its fundamentals. This shared governance is important: it means you are not dependent on a single company for your metadata to remain relevant.
An Agnostic and Universal Language
A crucial aspect of Schema.org is that it is completely agnostic regarding the technologies used to create your site. Regardless of whether your site is developed with a CMS like WordPress or Drupal, a platform like Wix or Shopify, or a static site hand-coded.
The Schema.org vocabulary works independently of these technologies, usually in the form of JSON-LD code embedded in your pages. This universality is essential: it ensures your metadata will be understood by all search engines, regardless of the tool you use to manage your site.
Why Is It Important for Artists and Cultural Organizations?
For creators and cultural distributors, online visibility is crucial but often complex to achieve with limited marketing budgets. Schema.org offers several concrete advantages:
- Better visibility in search results: Your events, shows, or exhibitions can appear in enriched formats (with dates, images, prices) directly in Google results.
- Precise referencing in event aggregators: Platforms like Google Calendar, Siri, or online cultural calendars can automatically extract the exact information from your events.
- Preparation for conversational AIs: When someone asks ChatGPT "What shows to see in Montreal this weekend?", your event has a better chance of being mentioned if its information is clearly structured.
- Connection to the cultural ecosystem: Structured data facilitates interoperability with other cultural platforms and sectoral databases.
- Creation of a sense network for AIs: Adding references to known entities (Wikidata, MusicBrainz, VIAF, etc.) for artists, works, and organizations helps weave a network of meaning that search engines and generative AIs can exploit. These connections allow your content to be better contextualized and appear in more relevant results, especially when users ask complex questions to AI assistants.
Integration of Schema Metadata
First Level: Structured Data, Essential Foundation
To understand Schema.org, one must first grasp the importance of structured data, which constitutes its fundamental base.
What Are Structured Data?
Structured data is simply information organized in a way that is easily readable and processable by machines. The key is in the structure: each information element has its defined place, and its relationship with other elements is explicit.
To understand the importance of structured data, let's compare two methods of publishing information about a cultural event:
Method 1: Unstructured Data
Imagine a formatted block of text in a WYSIWYG editor:
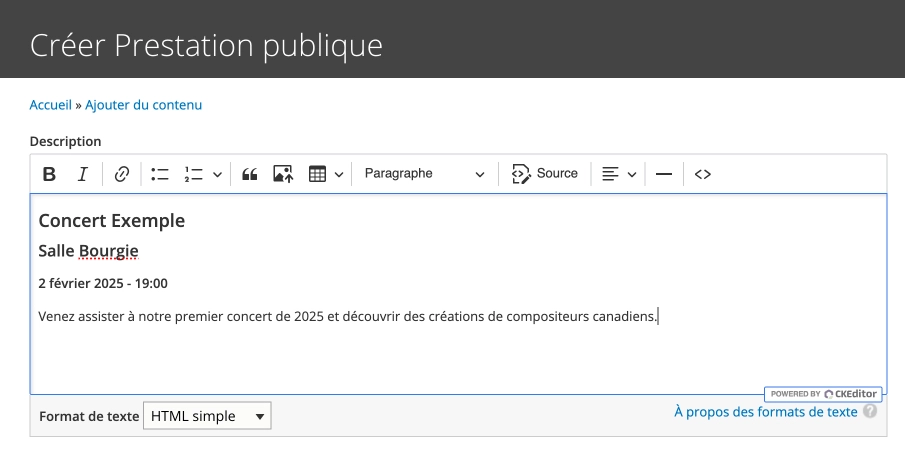
This presentation is clear for a human but problematic for machines. How to automatically distinguish the title, date, place? How to know if it's a concert, exhibition, or conference?
Method 2: Structured Data
In this approach, each information has its designated field:
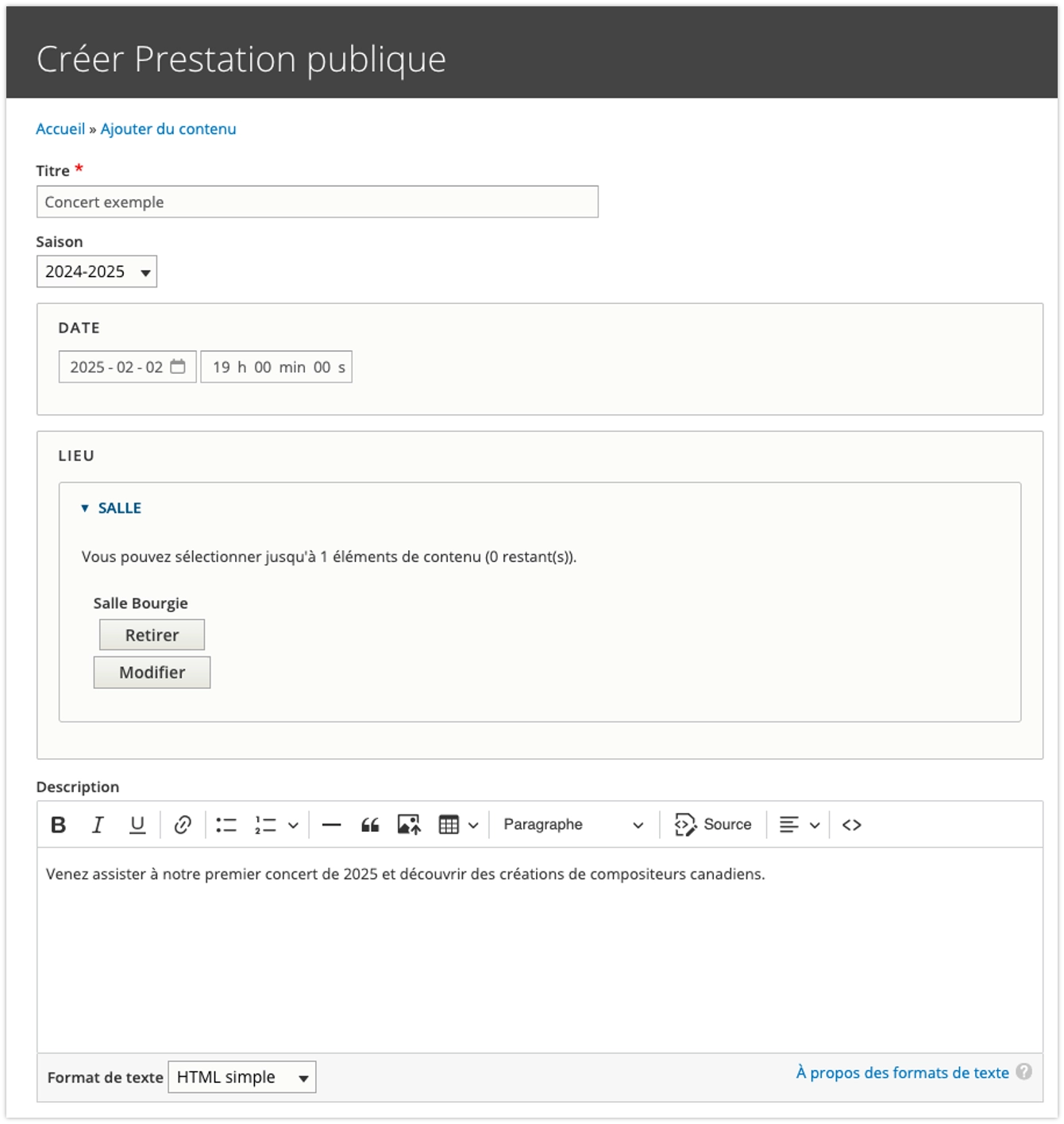
This method offers several advantages:
- Precision: Each information is identified without ambiguity,
- Flexibility: You can reorganize the display without changing the content,
- Reusability: The same content can be presented differently in various places,
- Shareability: Information can be easily extracted for other uses.
Why Structured Data Facilitates Schema.org
While it is technically possible to create Schema.org metadata manually for each page on your site, this approach quickly becomes tedious and error-prone. Structured data transforms this task into a much more efficient and automatable process.
Without well-organized structured data, you would have to write the JSON-LD code for each event, person, or place individually. Imagine having to manually create metadata for each of your concerts of the season! With structured data, on the other hand, you enter the information once in your usual forms, and an automated system generates the corresponding Schema.org metadata.
That's why we strongly recommend starting with good data structure before thinking about the technical implementation of Schema.org. A solid foundation will not only make implementation simpler but also easier to maintain in the long term.
Second Level: Data Modeling
Once you have adopted the structured data approach, the next step is to create a model that reflects the richness and complexity of artistic events and activities.
What Is a Data Model?
A data model is somewhat like the architectural blueprint of your content. It defines:
- The different types of content you manage (events, artists, places, etc.),
- The specific information for each type (name, date, address, biography, etc.),
- The relationships between this content (which artist participates in which event, in which place, etc.).
To illustrate, let's take the example of a typical cultural organization. You might need to manage:
- Events (concerts, shows, workshops),
- People (artists, composers, directors),
- Places (rooms, theaters, outdoor spaces),
- Works (musical pieces, texts, choreographies).
Each type of content has its characteristics. An event has a date and place, a person has a biography and contact information, a place has an address and capacity. The model organizes all of this coherently.
The Single Entry Principle: Avoid Redundancy
The fundamental idea of a good model is that information should be entered only once, in one place, and then linked to other elements as needed. This single entry approach is especially important in a web content management context. Here's why:
Economy of Effort: Instead of retyping "Salle Bourgie, 1380 Rue Sherbrooke O, Montréal" each time you create an event in this room, you create a single "place" entry that you can reuse indefinitely.
Error Reduction: If the room's address changes, you only have one place to modify instead of searching all occurrences in your database.
Uniformity of Information: Say goodbye to variations like "Salle Bourgie" vs "La Salle Bourgie" vs "Salle Bourgie of the Museum of Fine Arts" that can create confusion.
Database Efficiency: Your system stores the complete information of an artist, place, or work only once, then only keeps references in your events.
This relational data philosophy is particularly well-suited to modern content management systems (CMS), which allow easily creating these types of interconnected content.
The Advantages of a Well-Thought-Out Model
A well-designed data model offers several major advantages:
- Information Consistency: Data is organized logically and predictably.
- Duplication Avoidance: Each element (artist, place, work) is entered only once.
- Adaptability: The model can evolve to integrate new types of content.
- Ease of Maintenance: Information can be updated in one place.
- Preparation for Schema.org: The model can be easily translated into Schema.org vocabulary.
A Concrete Example: The Datascène Model
To illustrate these principles, let's look at a model developed specifically for the Quebec cultural sector. Datascène is a collective project that aims to create a repository of descriptive metadata for shows. Its objective: to facilitate the development of information systems associated with shows and improve their interoperability.
The interoperability sought by Datascène represents a major advantage: it facilitates the sharing and pooling of data between different organizations. Concretely, this can allow automatically propagating your events on collective calendars or facilitating information exchanges with your partners.
The Datascène model is formed of different classes, to which a number of properties are attached. The classes are connected to each other by precise relationships.
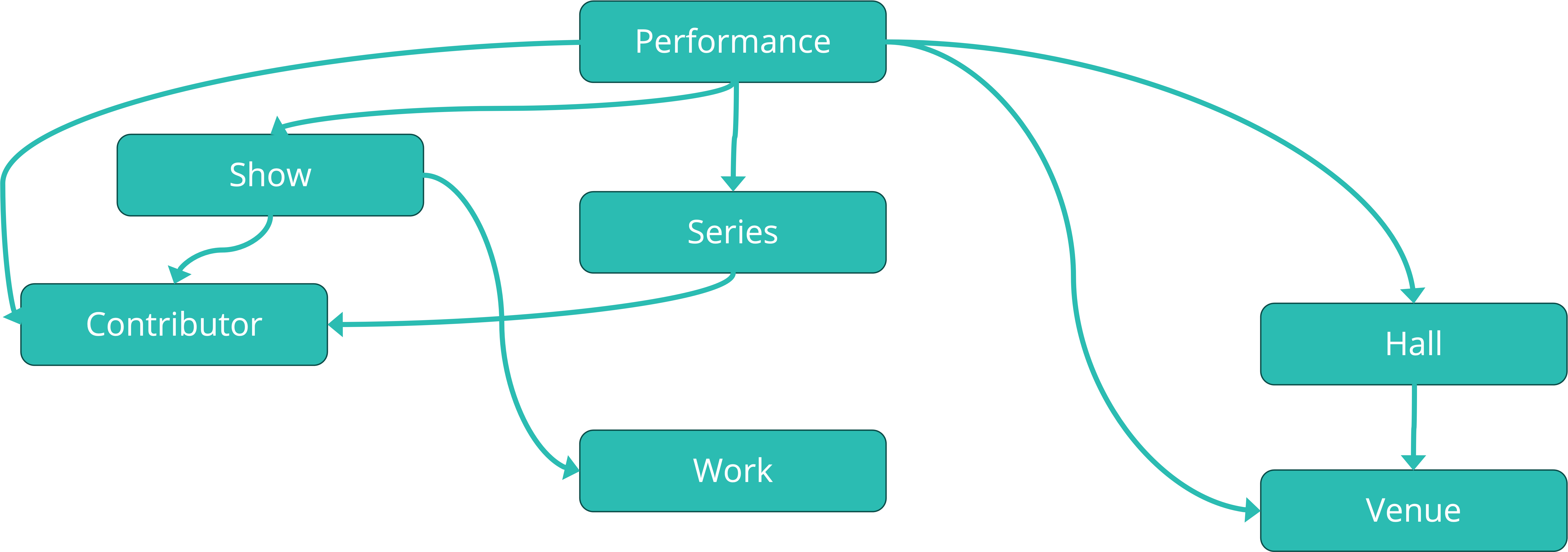
At Percumédia, we have developed very similar models for our clients in the cultural field. Our models are close to that of Datascène with a few differences:
- Contributors are by default segmented into more precise categories,
- Composers are separated from other contributors and directly associated with the work they created,
- The season class groups performances temporally.
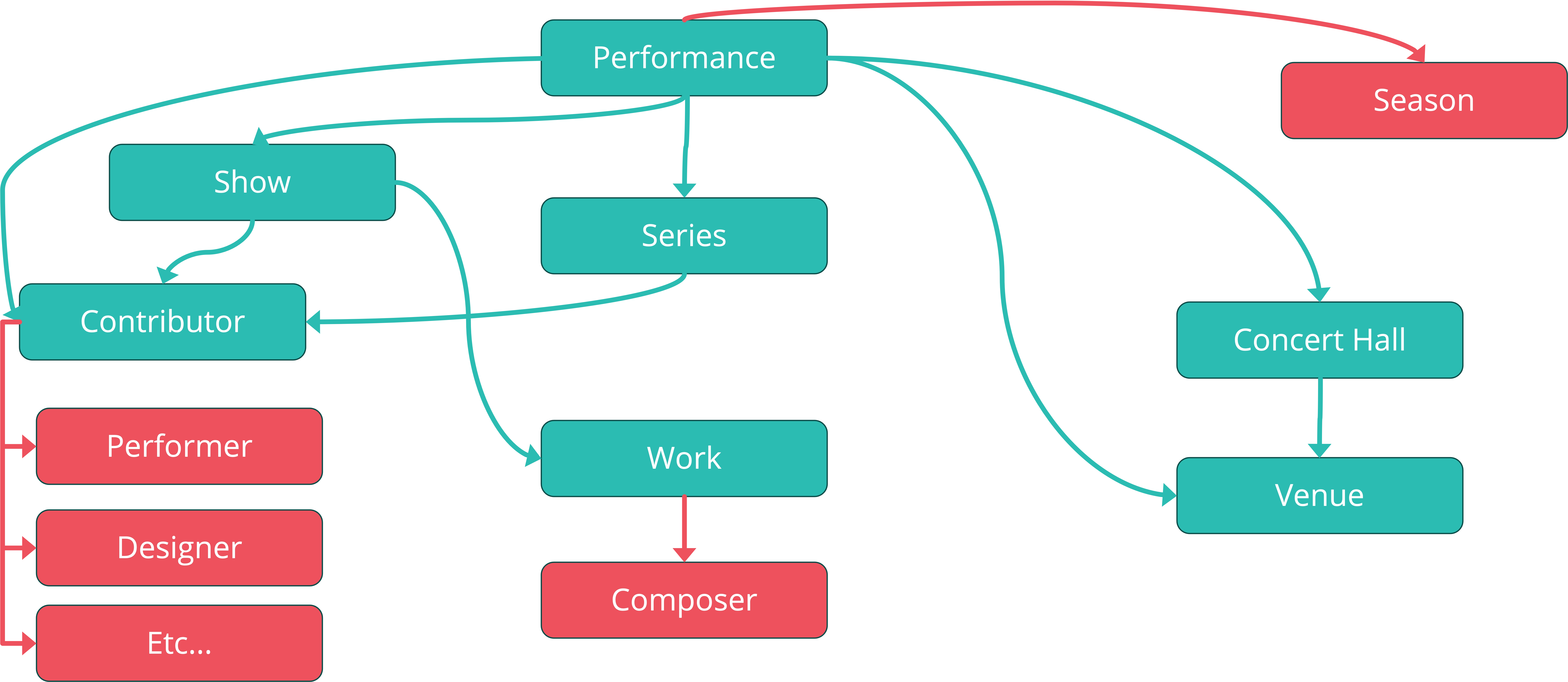
These models reflect the complexity of the content while respecting the single entry principle. An artist is defined only once, with their biography and contact information, and is simply "linked" to the different events they participate in.
Data modeling is the bridge between simple data structuring and its translation into Schema.org language. By adopting this single entry principle from the design stage of your site, you create a solid base that will greatly facilitate the implementation of Schema.org later on.
Third Level: Schema.org Integration into Your Site
Once you have well-structured data and a model adapted to your needs, you can proceed to the final step: the technical integration of Schema.org into your website.
How Does Schema.org Integrate Concretely?
Schema.org primarily uses a format called JSON-LD, which is embedded in your site's code but invisible to visitors. Here's a simplified example for a concert:

Our Approach at Percumédia: Complete Automation
At Percumédia, we have developed a specialized module for our Drupal sites that fully automates this process. Our module automatically generates Schema.org metadata from information already present in your database.
Concretely, here's how it works:
- You enter your information in your site's usual forms (event title, artists, place, date, etc.),
- Our module analyzes this structured data,
- It automatically generates the appropriate JSON-LD code according to Schema.org standards,
- This code is automatically inserted into each concerned page,
- Search engines can immediately interpret these metadata.
The Good News: No Additional Work!
On the sites where we have integrated our data model and Schema.org module, adding metadata does not represent any additional work for content editors. Once the system is configured, everything works automatically in the background.
For content editors and administrators, this simply means:
- Maintaining discipline in data entry: filling in all relevant fields,
- Preserving a consistent organization of information,
- Paying attention to details (complete dates, precise locations, etc.).
If your site is already structured with distinct content types (events, artists, places...), our approach allows adding Schema.org seamlessly, without changing your work habits.
Conclusion: Regaining Control of Your Digital Narrative
The implementation of Schema.org represents more than a simple technical investment that will continue to bear fruit in the long term. As search engines and conversational AIs evolve, sites with quality structured data will certainly benefit from a significant advantage. But there's something deeper at play.
As Tammy Lee of Culture Creates aptly expresses in her blog post Discoverability as an Act of Agency:
"In a digital world, discoverability must also be deliberate, or we risk losing control of the stories that define us."
This perspective transforms our understanding of Schema.org. Rather than passively undergoing how algorithms interpret your content, you actively regain control over how your organization, events, and creations are presented and understood online. You shift from a reactive approach to a proactive approach in your digital presence.
For artists and cultural organizations, often resource-limited but rich in quality content, this is a particularly empowering strategy. It allows you to "speak" directly to the machines that determine your online visibility without requiring large marketing budgets, but above all, without being entirely dependent on systems over which you have no control. Your content becomes not only more visible but also more faithful to your creative intention and values.
Do you want to regain control of your digital narrative and implement Schema.org on your site? Contact us to discuss your specific needs and get personalized support.